MySQL vs MongoDB (NoSQL) database MongoDB vs MySQL: Comparison Between Relational and Document Oriented Database Both are used for storing the data and free to use that is both comes under open-sources software. MongoDB might be unfamiliar at least to some of us as it is a relatively new compared to other established databases…
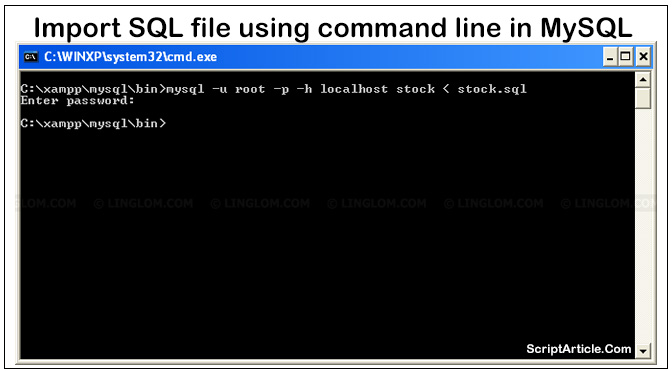
Import MySQL database using command line If you have a very large SQL dump file to import and you know very well that it is not very easy to import using phpMyAdmin, even if you split it in many pieces, it is also be hard using PHP script as it will time out after…
MySQL interview questions for experienced MySQL query for finding max and second max and nth max salary for a employee table using MySQL Suppose you have a table ’employee’ given as below —————————— | EmpId | Salary | | 2 | 2000 | | 3 …
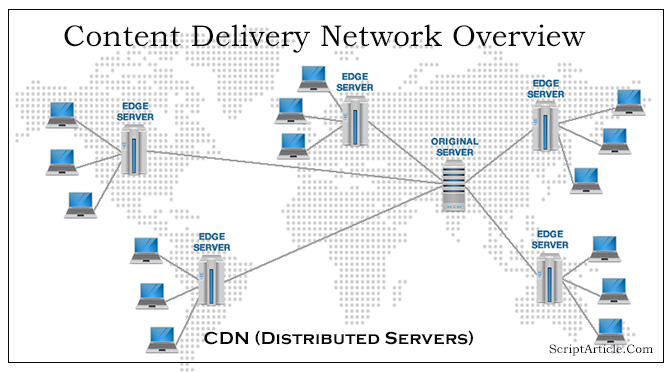
Content Delivery Networks (CDN) Hi Everybody, I think you all aware about the CDN (Content Delivery Networks). If not, don’t worry I am going to explain you what is CDN and how it works and how to know whether you site need CDN or not. In Short: A content delivery network (CDN)…
PHP Automatic Session Expire after X Minutes of Inactivity/Idle time Automatic session timeout/logout using php Session timeout is a notion and the only way you make you sure that no session ever will survive after X minutes of inactivity. Session timeout or Session expire depends on the server configuration or the relevant directives (session.gc_maxlifetime)…
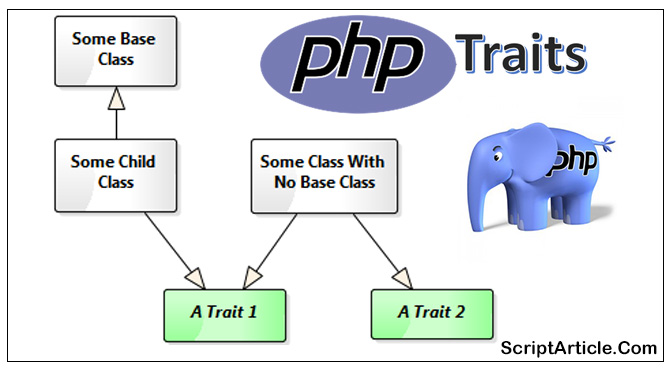
One of the problem of PHP as a OOP language is, the fact that you can only have single inheritance. This means your class can only inherit from one other class. PHP Traits (new feature was added in PHP 5.4) is kind of like a Mixin, allows you to mix Trait classes into an…