Advice Googlebot (Google) To Crawl Your Site
Googlebot is a Google’s web crawling bot or spider. This collects data from the web pages to build a searchable index for the Google search engine. Crawling is simply a process by which Googlebot visits new and updated pages, It uses an algorithmic programs determine which sites to crawl, how often, and how many pages to fetch from each site?
As Googlebot visits website it detects links (src and href) on each page and adds them to its list of pages to crawl. New sites, changes to existing sites, and dead links are noted and used to update the Google index.
If a webmaster wishes to control the information on their site available to a Googlebot,they can do so with the appropriate directives in a robots.txt file, or by adding the meta tag
<meta name=”Googlebot” content=”nofollow” />
to the web page.
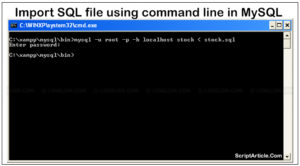
Once you’ve created your robots.txt file, there may be a small delay before Googlebot discovers your changes.
Googlebot discovers pages by visiting all of the links on every page it finds. It then follows these links to other web pages. New web pages must be linked to other known pages on the web in order to be crawled and indexed or manually submitted by the webmaster.